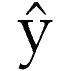
The ŷosokumo web service allows users to make predictions about new individuals based on data supplied about previously seen examples of similar individuals. An overview of the terminology, analytics and workflow for the service is given in the Yosokumo User Guide; this Yosokumo Protocol Specification document describes the interface exposed to clients by the core ŷosokumo service. This document contains the following sections:
- The Basics.
- Creating Studies.
- Providing Data.
- Predicting Responses.
- Study Administration.
- Granting Privileges.
- User Authentication.
- Protocol Summary.
The core ŷosokumo service uses a "RESTful" communications protocol to communicate with clients. Theoretically, a Representational State Transfer (REST) system is one in which system objects are viewed as resources whose state is changed by actors over time. More practically, a RESTful interface simply means that (i) clients make requests of the server by sending and receiving well-defined documents identified by URLs using HTTP methods and headers (as described in RFC 2616); and (ii) the server responds with similar documents as well as HTTP return codes and headers.
Before the ŷosokumo service performs an action for the client, the request is checked for authentication and authorization. Authentication means verifying that the request came from a recognized user; authorization means verifying that the user making the request has permission to do so. Users authenticate each of their requests by creating a cryptographically secure message digest using a secret key (an HMAC) of certain parts of the request and supplying this digest on an HTTP Authorization header. Permissions are granted by the owner (or another authorized user) of each resource by creating a "role" with specific privileges for a certain user and checked by the server on each request.
The client actor in the system is called a "user" and is identified by a sixteen character, case sensitive string (called a "user identifier") that is provided (along with a secret key) at enrollment. The primary resource in the system is the "study", identified alternatively by a URI or by a case sensitive string (called a "study identifier") that is assigned by the service when the study is created. The study is a container that serves primarily to hold other resources, especially the "table" and "model" resources -- representing the user supplied training data and the predictive model built from that data by the service.
In general, clients use the GET method to obtain a document reflecting the current state of a resource; the POST method to send a document to be added to an existing resource; the PUT method to send a document that changes or updates an existing resource; and the DELETE method to remove permanently a resource from the system. For example, users make a Get Study request to obtain a document showing information about the study, including the URLs of its subordinate resources; a Post Table request to provide a block of relevant training data to the service; a Put Role request to update the privileges of a certain user on a study; and a Delete Role request to remove all privileges for a certain user on a study. (A complete list of allowed method-resource request combinations is available in Appendix A.)
Also characteristic of RESTful systems, ŷosokumo clients are expected to navigate the system by following links or "locations" provided by the service in documents that clients receive. For example, when a client uses the GET method to obtain a document representing a study, that document will include the locations of related or subordinate resources like the study's table and model. The client then may choose to make an appropriate request — such as Post Table — to interact with those resources, or may choose to ignore them. In this manner, like a person clicking the familiar hyperlinks on a web page, a client can dynamically create its own path through the resources that comprise the system. It is important to note that the locations provided by the server to the client must be treated as opaque handles or identifiers of the resources which they identify; the proper way to navigate the system is to follow the links given by the server. Even if an examination of the locations seems to reveal a pattern that can be anticipated, the server can at any time choose a different (more efficient or more secure) scheme for naming its resources and break applications that incorrectly attempt to build location URI's by themselves.
Resources are abstract entities; the documents that represent them are concrete. This means that, in addition to exchanging documents whose contents have an agreed upon meaning, the client and server must format the documents in an agreed upon manner. The ŷosokumo system accepts documents formatted in four (4) Data Interchange Formats (DIFs): XML, JSON, Google Protocol Buffers and ASN.1. On each request the client must indicate the DIF of the document it is sending (if any) using the HTTP Content-Type header; the client may also specify its preferred DIF for the document it expects to receive (if any) using the HTTP Accept header. The canonical specification for protocol documents is given (in ASN) in Appendix C.1; the corresponding formats for XML are shown in Appendix C.2, for JSON in Appendix C.3 and for protocol buffers in Appendix C.4. (For exposition, this document shows protocol documents in their XML format, without the normal namespace declarations or prefixes, and formatted for readability.)
Taken together, this means that a typical request-response exchange between a client and the ŷosokumo server might look like:
Client:
GET /study.ABCDEF9876543210 HTTP/1.1 User-Agent: curl/7.19.6 Accept: */* Host: yosokumo.ws Date: Fri, 01 Jan 2010 01:04:16 +0000 Authorization: yosokumo 1234567890ABCDEF:Od9v9Q/bn6XhZeLbnClxc/2pkwPQKA9f49Q60FXDZGQVZgIT5LkaXb5k6SJnVRlSLWOUl9C6qZ5CBPhIl8JsvA==
Server:
HTTP/1.1 200 OK Date: Fri, 01 Jan 2010 01:04:17 GMT Server: Apache/2.2.11 (Unix) Content-Length: 621 Content-Type: application/yosokumo+xml Content-MD5: NBBCCBRJfFTrstKYpsf/cw== <?xml version='1.0' encoding='UTF-8'?><yx:study xmlns:yx='http://yosokumo.ws/xml' yx:study_identifier='ABCDEF9876543210' . . . />
The following sections give an overview of each of the requests that a client may make of the server and the documents exchanged. Client requests usually take only one form, and these forms are shown in the text below. Since the form of the response varies depending on the result (success or failure) of the request, responses (other than the documents delivered) are generally not shown in the text. A complete list of mandatory and optional parts of each request and all possible responses and their parts can be found in Appendix B; a full list of the attributes (along with valid values) and subordinate resources of each protocol document type can be found in Appendix C.1.
The following typographic conventions are used throughout this document: HTTP requests and responses are shown block indented in courier type; the contents of full protocol documents are shown logically indented in courier type; when shown inline in the text, document attribute names are shown unquoted in courier_type, and attribute values are shown single-quoted in 'courier-type'; request-method combinations that together form client requests are shown in Smallcaps Type.
Post Catalog
In an ordinary workflow, the first task for the user is to create a study. In order to do this, the user makes a Post Catalog request to the service. The "catalog" is a resource that contains a list, indexed by study identifier, of all the studies that a certain user has privileges on. By posting a study document to the catalog, the user asks the system to lengthen this list by creating a new study owned by the requesting user. The form of the Post Catalog request is:
POST catalog-location HTTP/1.1
Date: date
Host: host
Content-Type: content-type
{Optional headers}
Authorization: yosokumo user-identifer:request-digest
<study . . . />
The study resource serves as a container for all resources associated with an analytic project. Its attributes include the study_identifier, study_name, type, and statusof the study; its subordinate resources include the "table", "model", "panel" and "roster". (described below). The study identifier is assigned, and the subordinate resources are automatically created by the service when the study is created. The name, type, and status attributes of the study can be set by the user at creation, so the study document that is posted to the catalog typically contains only some combination of these attributes. By including an attribute in the posted study document, the client asks the server to set the initial value of that attribute to the value shown in the document. Attributes that are valid in a study document, but that cannot be set by the user (such as the study_identifier attribute) are ignored.
The study_name attribute contains a string up to 256 characters in length describing the study; it may be changed at any time. If the name attribute is not included in the posted study document, the default value is an empty string.
The study type attribute indicates the quality of the predictands associated with subjects in the study and therefore the type of predictive model that will be built for the study. Valid values are: 'class' indicating the predictand is categorical and nominal; 'rank' indicating the predictand is categorical, but also ordinal; 'number', indicating that the predictand is continuous and ratio; and 'chance' indicating the predictand represents a probability given as a continuous value between zero and one inclusive. The type attribute may not be changed after it has been set at study creation. If the type attribute is not included in the posted study document, the default value is 'number'.
The status attribute describes the state of the study. Valid values are: 'running', meaning the service is accepting data into the study's table, analyzing the data to improve the study's predictive model and estimating predictands based on the model; 'paused', meaning the service is no longer accepting or analyzing data, but is still estimating predictands for the study based on the current model; and 'stopped', meaning the service is neither accepting nor analyzing data, and is not estimating predictands for the study. The status of a study can be changed at any time. If the status attribute is not included in the posted study document, the default status is 'running'.
The visibility attribute describes whether unidentified users can get estimated predictands from the model of the study. Valid values are: 'private', meaning only users that are authenticated and authorized may make a Get Model request for the study; and 'public', meaning any web client may make a Get Model request for the study. The visibility of a study can be changed at any time. If the visibility attribute is not included in the posted study document, the default visibility is 'private'.
Taken together, a posted study document might look like:
<study study_name='Trial One' type='class' status='running' visibility='public'/>
Since all three attributes may be omitted, however, the following document is minimally sufficient for the Post Catalog request:
<study/>
If the Post Catalog request is successful, the server returns a status code of 201 Created; in addition, the server returns a full study document containing the values of all the study's attributes and the locations of all the study's subordinate resources (see below).
Because the location (URI) of the user's catalog may be unknown at the outset, the user can alternatively create a study by making a Post Service request. This request is equivalent in all respects to the Post Catalog request, except that, in the request, the URI listed in the HTTP request line is the URL of the ŷosokumo service (/yosokumo.ws) and, in the response, the server adds the HTTP Location header that contains the location of the catalog of the requesting user that may be used for later requests.
Get Study
At any time, the user can request the current full study document by making a Get Study request. The form of the Get Study request is:
GET study-location HTTP/1.1
Date: date
Host: host
{Optional headers}
Authorization: yosokumo user-identifer:request-digest
As with all GET requests, no document should be posted as part of the Get Study request. Upon success, the server returns a status code of 200 OK and a full study document of the form:
<study study_identifier='...' study_name='...' type='...' status='...' visibility='...' location='...'> <owner user_identifier='...' user_name='...'/> <table location='...'/> <model location='...'/> <panel location='...'/> <roster location='...'/> </study>
In addition to the attributes described in connection with the Post Catalog request above, the full study document contains the study_identifier attribute, a case-sensitive string that uniquely identifies the study and the location of the study resource (which should correspond to the URI appearing in the GET request) that should be used in other client requests. Additionally, the full study document indicates the user_identifier and user_name of the owner (creator) of the study, as well as the location of each of the subordinate resources contained in the study (described below).
Get Catalog
In order to obtain a list of all studies that the requesting user has any privileges on, the user may make a Get Catalog request. The form of the request is:
GET catalog-location HTTP/1.1
Date: date
Host: host
{Optional headers}
Authorization: yosokumo user-identifer:request-digest
Again, no document is included in this GET request. Upon success, the server returns a status code of 200 OK and a catalog document of the form:
<catalog user_identifier='...' user_name='...' location='...'> <study . . . > . . . </study> <study . . . > . . . </study> . . . <study . . . > . . . </study> </catalog>
The catalog document shows the identifier and name of the user of the catalog, as well as the catalog location attribute which should contain a value corresponding to the URI appearing in the GET request line. By default, the catalog document contains abbreviated study documents that include primarily the identifier and location of each study. The client may override this default by including in the Get Catalog request the optional application HTTP header x-yosokumo-full-entries and setting the value to 'on', in the form:
x-yosokumo-full-entries: on
When this header is included, the study documents contained in the catalog are of the same form as the document returned by a successful Get Study request.
Post Table
In order to construct predictive models, the service examines data supplied by a client. Users provide data for study subjects with known predictands by making a Post Table request and sending a "block" document along with it. A block may contain all or only part of the data available for examination; it may be oriented horizontally as "specimens" (or rows) or vertically as "predictors" (or columns); it may overlap with a previously supplied block; it may be "ragged", having different numbers of data values for each specimen or predictor; and, it may be sent by any authorized user at any time (provided the study is running). By posting a block to the study's table, the user requests that the data supplied in the block be added to the dataset considered in constructing or improving the study's model.
The form of the request is:
POST table-location HTTP/1.1
Date: date
Host: host
Content-Type: content-type
{Optional headers}
Authorization: yosokumo user-identifer:request-digest
<block . . . />
Because the POST request requires that the client send a document, the client must include the HTTP Content-Type header to indicate the DIF of the document included in the request.
The block document may take three different forms depending on the value of the type attribute. The simplest block has the form:
<block study_identifier='...' type='...'/>
The study_identifier attribute is optional; when supplied by the client, the server verifies that the study identifier in the block matches the identifier of the study containing the table to which the client is posting. If it does not match, the server responds with a 409 Conflict status code.
The type attribute can take one of three values: (i) 'row', indicating that the block is horizontally oriented and contains specimens; (ii) 'column', indicating that block is vertically oriented and contains predictors; or (iii) 'empty', indicating that the block contains neither predictors nor specimens. An empty block cannot carry information, but can be used to test whether the requesting user has permission to post to the table or whether the study is 'running' and therefore accepting blocks into the table. When the type attribute is not supplied, the server determines the block type based on the contents of the block.
When the block type is 'row', the block may contain zero or more specimens and take the form:
<block type='row' study_identifier='...'> <specimen . . . > . . . </specimen> <specimen . . . > . . . </specimen> . . . <specimen . . . > . . . </specimen> </block>
Each specimen represents a single observation, record, or row of data. Each specimen takes the form:
<specimen key='...' status='...' weight='...' type='...' value='...'> <cell . . . /> <cell . . . /> . . . <cell . . . /> </specimen>
The specimen key is the identifier of the record or row; it must be a natural number less than 264-2. If the key is absent, null (according to the rules of each DIF), or set to zero, the specimen is considered anonymous.
The status attribute provides a logical delete facility; valid values are 'active', meaning the specimen should be considered when constructing the model; and 'inactive', meaning the specimen should not be considered when constructing the model. If not provided, the default is 'active'.
The weight indicates the sampling weight of the specimen; it must be a natural number greater than zero (0) and less than 264 - 2. The default value is one (1).
The type and value attributes together provide the numeric predictand's value for the specimen; the value provides the quantity of the predictands and the type describes how to interpret and store the quantity. Valid values for the type attribute are: 'natural', indicating the predictand is a positive whole number (including zero) in the range [0,264-1] ; 'integer', indicating the predictand is a positive or negative whole number in the range [-263,263-1]; 'real', indicating the numeric predictand contains an integral and fractional part and should be stored as precisely as the possible on the server; and 'empty', indicating that the predictand is unknown for this specimen. If the type is not supplied, it defaults to 'real'. If the value is not supplied, is unintelligible, or is an a format inconsistent with the indicated type, the type is set to 'empty'.
Each specimen may contain zero or more "cells". A cell represents the value of single predictor for the specimen and takes the form:
<cell name='...' type='...' value='...'/>
The name is a whole number greater than zero (0) and less than 264-2; it corresponds to the name of an expressed or implied predictor in the table. Since a specimen may omit any predictor about which it has no information, specimens in the same block may have different lengths and contain differing subsets of table predictors. The mandatory name in each specimen cell removes ambiguity in mapping the cells in each specimen to the predictors in the table.
The type and value attributes play similar roles in cells as in specimens; the value provides the numeric quantity of the predictor measurement and the type indicates the interpretation and storage of that quantity. All the types available for the specimen predictand are also available for cells. In addition, the cell type attribute may contain the value 'special', indicating that the value is a positive whole number greater than zero and is a special (orthogonal or error code) value for the predictor.
When the block type is 'column', the block may contain zero or more predictors and take the form:
<block type='column' study_identifier='...'> <predictor . . . > . . . </predictor> <predictor . . . > . . . </predictor> . . . <predictor . . . > . . . </predictor> </block>
Each predictor represents a single attribute, feature or column of data. Each predictor takes the form:
<predictor name='...' status='...' type='...' level='...'> <cell . . . /> <cell . . . /> . . . <cell . . . /> </predictor>
The predictor name is the identifier of the feature or column; it must be a natural number greater than zero (0) and less than 264-2. Its presence is mandatory.
The status provides a logical delete facility; valid values are 'active', meaning the predictor should be considered when constructing the model; and 'inactive', meaning the predictor should not be considered when constructing the model. The default is 'active'.
The type attribute describes the quality of the predictor and determines the statistical operations that can be performed on the feature. Valid values are: 'categorical', meaning the feature takes on discrete values; and 'continuous', indicating the feature may take any real value. The default is 'continuous'.
The level attribute indicates the level of measurement for the feature. Valid values are: 'nominal', meaning the values are merely names for the states measured by the feature, without any implied order among them; 'ordinal', meaning the feature takes (usually discrete) values that can be ranked, but the distance between the values is not meaningful; 'interval', meaning the predictor values can be ranked and the distance between adjacent values is uniform; and 'ratio', meaning the the values taken by the predictor are interval and that the ratios between any two values are uniform as well.
As with specimens, each cell within a predictor represents the value of single specimen for the predictor and takes the form:
<cell key='...' type='...' value='...'/>
Predictor cells are entirely analogous to specimen cells, except that each predictor cell has a key (rather than a name) that corresponds to the key of an expressed or implied specimen in the table. As in specimens, the mandatory key in each predictor cell removes ambiguity in mapping the cells in each predictor to the specimens in the table.
If a Post Table request is successful, the server responds with a 202 Accepted status code and returns no document to the client. If the posted block document is malformed -- either because it is unparsable according to the rules of its DIF or because its contents are invalid according to this protocol -- the server responds with a 400 Bad Request status code and returns a message document that provide details on the error.
At any time after the creation of a study, a user may ask the server to estimate the unknown predictands for new prospects. In order to obtain such predictions, users make either a Post Model or a Get Model request; the GET request is limited to a single prospect, but allows for the specimen representing that prospect to be placed on the HTTP request line; the POST request allows the client to obtain estimated predictands for multiple prospects on a single call, but requires that the client include a block document with the request.
Post Model
The form of the Post Model request is:
POST model-location HTTP/1.1
Date: date
Host: host
Content-Type: content-type
{Optional headers}
Authorization: yosokumo user-identifer:request-digest
<block . . . />
The form of the posted block is the same as for the Post Table request, except that the block type must be either 'row' or 'empty'. Vertical blocks with type 'column' are not permitted in Post Model requests. The block should contain one specimen for each prospect for which the clients desires a prediction. Each cell in each specimen in the posted block should contain the name of a predictor in the study table and the type and value of that feature measured for that specimen. If present, predictand information for the specimen — the specimen type and value attributes — is ignored by the server.
Upon success, the server returns either a status code of 204 No Content, if the posted block was of type 'empty', or a status code of type 200 OK along with a block containing estimated predictands, if the posted block was of type 'row'. The block returned by the server is of the same type and form as the posted block; it contains as many specimens as were contained in the posted block; and each specimen is identified by the key (if any) contained in each posted specimen. By default, the block returned by the server does not contain the specimen cells provided by the client in the posted block. The client may override this default by including in the Post Model request the optional application HTTP header x-yosokumo-echo-prospects and setting the value to 'on', in the form:
x-yosokumo-echo-prospects: on
Get Model
The Get Model request allows a client to obtain the estimated predictand for a single prospect. Ordinarily, the form of the Get Model request is:
GET model-location?escaped-encoded-specimen HTTP/1.1
Date: date
Host: host
{Optional headers}
Authorization: yosokumo user-identifer:request-digest
However, when the visibility of a study is set to 'public', the client may omit the Authorization HTTP header when making a Get Model request.
The client must include a prospect specimen on the request line with this request. A question-mark symbol separates the model location from the prospect specimen. The escaped, encoded prospect specimen consists of a URL-escaped string comprised of an optional key-value pair (indicating the key of the specimen) followed by zero or more name-value pairs, separated by ampersand symbols, each containing the numeric name of a table predictor and the measured value for that predictor formatted to indicate the type of the value. More formally, the syntax of the encoded-specimen string (in EBNF production rules) is:
| encoded-specimen | = | [ key-pair , { "&" , name-pair } | name-pair , { "&" , name-pair } ] ; |
| key-pair | = | "K" , "=" , [ "0" | identifier ] ; |
| name-pair | = | identifier , "=" , [ value ] ; |
| value | = | natural-value | integer-value | real-value | special-value ; |
| natural-value | = | "0" | ( numeral , { digit } ) ; |
| integer-value | = | ( "+" | "-" ) , natural-value ; |
| real-value | = | integer-value , ( fractional-part | [ fractional-part ] , exponential-part ) ; |
| fractional-part | = | "." , digit , { digit } ; |
| exponential-part | = | "E" , ( "+" | "-") , ( digit , { digit } ) ; |
| special-value | = | "$" , ( numeral , { digit } ) ; |
| numeral | = | "1" | "2" | "3" | "4" | "5" | "6" | "7" | "8" | "9" ; |
| digit | = | "0" | numeral ; |
| identifier | = | numeral , { digit } ; |
Note in particular: (i) the encoded-specimen may be entirely empty; (i) the specimen key, if present, must appear first and its value may be empty, zero, or an identifier; (ii) the identifier in a name-value pair refers by name to a predictor in the study table; (iii) the value in a name value pair may be omitted, indicating an explicitly empty or unmeasured value; (iv) natural values may be zero, but contain no leading zeros if non-zero; (v) integer values must include a leading sign symbol; (vi) real values must include a leading sign symbol and either (1) a decimal point followed by at least one digit or (2) an exponential indicator followed by a sign symbol and at least one digit (they may contain both); and (vii) special values are always strictly positive and preceded by a dollar symbol. For example, the encoded specimen:
K=1000&1=&2=2&3=+3&4=-4.0&5=$5
indicates that the specimen key is 1000; the table predictor named "1" is unmeasured for this specimen (its value is omitted); table predictor "2" has a natural value of two (2); predictor "3" has integer value three (3); predictor "4" has real value of negative four (-4); and predictor "5" has a special value coded as five (5).
As in the Post Model request, any predictor not specified in the encoded-specimen is treated as unmeasured (or type 'empty') when predicting the specimen's predictand. When the encoded-specimen is zero-length (that is, contains neither a key-value pair nor any name-value pairs), the service interprets the specimen as "empty" (and treats the request as analoguous to a Post Model request with an empty block).
Schemes for URL- (or "percent-") escaping vary, but all widely adopted variants are accepted by the server. For the limited purposes of this protocol, it suffices for proper URL-escaping that the following characters appearing in the encoded specimen be replaced by the indicated character sequences:
| Character | Replacement |
| $ | %24 |
| & | %26 |
| + | %2B |
| = | %3D |
Using this simplified scheme, the encoded specimen example shown above would be URL-escaped:
K%3D1000%261%3D%262%3D2%263%3D%2B3%264%3D-4.0%265%3D%245
Upon success, the server returns a status code of 204 No Content if the query string appended to the model location in the request line was zero-length (an "empty" specimen), or a status code of 200 OK along with a specimen document containing the estimated predictand for the provided specimen. The returned document is identical in form to the specimen portion of a block document; it repeats the key (if any) provided in the encoded specimen and provides the type and value of the estimated predictand. As in a Post Model request, the specimen returned from a Get Model request does not contain the "cells" encoded on the request line unless the client includes in the request the x-yosokumo-echo-prospects: on HTTP header.
For the Get Model request only, the client may request that the returned specimen document be encoded as plain text by setting the HTTP header Accept: text/plain. A specimen document encoded as plain text has the following syntax (an extension of the EBNF production rules given above for encoded specimens):
| specimen-document | = | [ predictand-value ] , [ ":" , encoded-specimen ] , CR , LF ; |
| predictand-value | = | natural-value | integer-value | real-value ; |
| CR | = | ? US-ASCII carriage return character x'0D' ? ; |
| LF | = | ? US-ASCII line feed character x'0A' ? ; |
If the predictand-value is not included in the document, it indicates that the predictand type is 'empty'; otherwise the predictand type and value are encoded together as in the values of the "cells" of an encoded specimen. The encoded-specimen (and colon delimiter) appear only if the request included the x-yosokumo-echo-prospects: on HTTP header. A CRLF sequence is always present to mark the end of the document. Note that the returned plain text document is not URL-escaped.
Get Panel
In order to obtain administrative information about a study, the user makes a Get Panel request. The form of the request is:
GET panel-location HTTP/1.1
Date: date
Host: host
{Optional headers}
Authorization: yosokumo user-identifer:request-digest
No document should be included in the request. Upon success, the server returns a status code of 200 OK and a panel document of the form:
<panel study_identifier='...' location='...'> <control study_identifier='...' location='...'> <study_name>...</study_name> </control> <control study_identifier='...'> <type>...</type> </control> <control study_identifier='...' location='...'> <status>...</status> </control> <control study_identifier='...' location='...'> <visibility>...</visibility> </control> <control study_identifier='...'> <block_count>...</block_count> </control> <control study_identifier='...'> <cell_count>...</cell_count> </control> <control study_identifier='...'> <prospect_count>...</prospect_count> </control> <control study_identifier='...'> <creation_time>...</creation_time> </control> <control study_identifier='...'> <latest_block_time>...</latest_block_time> </control> <control study_identifier='...'> <latest_prospect_time>...</latest_prospect_time> </control> </panel>
Just as in the study and other documents, the study_identifier attribute is the identifier created by the service when the study was created. The location attribute indicates the URI of the panel resource and should match the URI included on the client's request line. The body of the panel document contains a list of controls. A control may be directly reset if it contains a location attribute; otherwise it is a read-only value. The first four controls — containing the study_name, type, status, and visibility — correspond to the study attributes set (or defaulted) via the study document when the study was created.
The block_count reports the number of posted blocks that have been accepted into the study table; the cell_count is the total number of cells contained in the blocks reported in the block count. The prospect_count is the total number of specimens contained all Post Model and Get Model requests for the study.
The creation_time indicates the UTC time the study was created. The latest_block_time indicates the UTC time that the service accepted the most recent block into the study table. The latest_prospect_time indicates the UTC time of the most recent Post Model or Get Model request.
Get Control
In order to obtain a separate document for a resettable panel control, the client makes a Get Control request. The request has the form:
GET control-location HTTP/1.1
Date: date
Host: host
{Optional headers}
Authorization: yosokumo user-identifer:request-digest
Upon success, the server returns a status code of 200 OK along with the requested control document. The form and content of the returned document is the same as the corresponding list entry in the full panel document.
Put Control
In order to change the value of a resettable panel control, the client makes a Put Control request. It has the form:
PUT control-location HTTP/1.1
Date: date
Host: host
Content-Type: content-type
{Optional headers}
Authorization: yosokumo user-identifer:request-digest
<control . . . />
The form of the control document sent with the request is the same as the corresponding list entry in the panel document or the document returned by the server in a successful Get Control request for the same control:
<control study_identifier='...'> <study_name>...</study_name> OR <status>...</status> OR <visibility>...</visibility> </control>
The study_identifier attribute is optional; when supplied by the client, the server verifies that the study identifier in the control matches the identifier of the study containing the control to which the client is posting. If it does not match, the server responds with a 409 Conflict status code. If present, the location attribute is ignored.
The control document must contain exactly one of the attributes study_name, status, or visibility. Valid values (and their meanings) for the study_name, status, and visibility attributes are the same as for the corresponding attributes of the study and panel documents.
Upon success, the server returns a status code of 204 No Content.
Delete Study
A study in any status can be deleted by an authorized user at any time. To completely and unrecoverably purge a study and all its subordinate resources (including its table, model, and roster), the user makes a Delete Study request with the form:
DELETE study-location HTTP/1.1
Date: date
Host: host
{Optional headers}
Authorization: yosokumo user-identifer:request-digest
No document is sent with the DELETE request. Upon success, the server returns a status code of 204 No Content.
When a study is created, the user who creates the study is given authorization to perform any action on that study. More precisely, the service creates a role for the requesting user on the newly created study in which all privileges are set to true, and inserts the role into the roster for the new study. A "role" is a collection of privileges for a particular user on a particular study. A "roster" is the collection of all roleholders for a study.
Get Role
In order to see the privileges granted to a particular roleholder, an authorized user makes a Get Role request. The form of the request is:
GET role-location HTTP/1.1
Date: date
Host: host
{Optional headers}
Authorization: yosokumo user-identifer:request-digest
No document is sent with the GET request. Upon success, the server responds with a status code of 200 OK and returns a role document of the form:
<role location='...'> <roleholder user_identifier='...' user_name='...'/> <privileges get_study='...' delete_study='...' get_roster='...' post_roster='...' get_role='...' put_role='...' delete_role='...' get_panel='...' get_control='...' put_control='...' post_table='...' get_model='...' post_model='...' /> <study study_identifier='...' study_name='...'/> </role>
The location attribute gives the URI of the role and should correspond to the URI given by the client on the request line.
The user_identifier attribute shows the sixteen character identifier issued to the user at enrollment — the same identifier the roleholder inserts into the Authorization header to make requests. The user_name is the name chosen by the user at enrollment.
The study_identifier and study_name attributes show the identifier and name of the study for which the role is valid.
Each of the thirteen privilege attributes corresponds in the obvious way to a protocol method-resource request type. For each privilege attribute, the valid values are 'true', meaning the roleholding user is authorized to make that request for the study, or 'false' indicating the roleholding user is forbidden from making that request for the study. Note that the Get Catalog/Get Service and Post Catalog/Post Service request types have no corresponding attribute in the role document. This is because the authority to create a new study or see the catalog of the studies on which the requesting user has a role are privileges extended by the service itself and are not connected with a single existing study. In general, all enrolled users have the authority to make Get Catalog/Get Service and Post Catalog/Post Service requests.
Post Roster
In order to grant access to another user for a study, an authorized user creates a new roleholder for study by making a Post Roster request. The request takes the form:
POST roster-location HTTP/1.1
Date: date
Host: host
Content-Type: content-type
{Optional headers}
Authorization: yosokumo user-identifer:request-digest
<role . . . />
Analogous to the Post Catalog request, this request instructs the service to lengthen the study's roster by introducing a new roleholder. The posted role document is of the same form as that returned by the server during a Get Role request. The posted document must include the user_identifier attribute to specify which user is to be authorized for the study. If present, the user_name attribute is ignored.
The study_identifier attribute is optional; when supplied by the client, the server verifies that the study identifier in the role document matches the identifier of the study containing the roster to which the client is posting. If it does not match, the server responds with a 409 Conflict status code. If present, the study_name attribute is ignored. If neither the study_identifier nor the study_name attribute is included, the study portion of the role document may be omitted entirely.
Each recognized attribute in the privileges portion of the document is optional; if present, the valid values for each are 'true', 'false', and 'null' (according to the rules of the DIF used). For the Post Roster request, if a privilege is omitted or set to 'null' in the role document, the corresponding privilege will be set to 'false' in the newly created role; that is, the requesting user must grant explicitly each desired privilege for the new roleholder.
Get Roster
In order to see the complete list of roleholders for a study, a user makes a Get Roster request of the form:
GET roster-location HTTP/1.1
Date: date
Host: host
{Optional headers}
Authorization: yosokumo user-identifer:request-digest
No document is included in this request. Upon success, the server returns a status code of 200 OK and a roster document of the form:
<roster study_identifier='...' study_name='...' location='...'> <role . . . > . . . </role> <role . . . > . . . </role> . . . <role . . . > . . . </role> </roster>
The study_identifier and study_name show the identifier and name of the study to which the roster belongs. The location attribute shows the URI of the roster and should match the URI appearing in the request line. By default, the roster document contains abbreviated role documents that include only the location of each role. The client may override this default by including in the Get Roster request the optional application HTTP header x-yosokumo-full-entries and setting the value to 'on', in the form:
x-yosokumo-full-entries: on
When this header is included, the role documents contained in the catalog are of the same form and meaning as the document returned by a successful Get Role request.
In general, in order to make a particular method-resource request for a particular study, the requesting user must have a role on the referenced study in which the corresponding method-resource privilege is set to true. There are two related exceptions to this rule: (i) a user who has a role on a study that does not include the get_roster privilege is authorized nevertheless make a Get Roster request for the study in order to obtain a redacted roster containing only his role; and similarly, (ii) a user who has a role on a study that does not include the get_role privilege is nevertheless authorized to make a Get Role request for the study only to the location for his own role. The former exception exists so that any roleholder can obtain the location of his own role for a study; the latter exception exists so that any roleholder may examine the privileges he has been granted for a study.
Put Role
In order to change the privileges of an existing roleholder, an authorized user makes a Put Role request. The form of the request is:
PUT role-location HTTP/1.1
Date: date
Host: host
Content-Type: content-type
{Optional headers}
Authorization: yosokumo user-identifer:request-digest
<role . . . />
The role document sent by the client is of the same form as that sent during the Post Roster request. However, unlike the Post Roster request, for the Put Role request, if a privilege is omitted or set to 'null' in the role document, the corresponding privilege is left unchanged in the existing role. In general, all and only those privileges that are included in the document and explicitly set to 'true' or 'false' are updated by the Put Role request. An exception to this general rule occurs when the user who created the referenced study attempts to update his own role for that study and includes the get_roster, post_roster, get_role, put_role or delete_role privilege in the sent role document; in that case, each of these privileges is treated as if it were omitted, the corresponding privilege is left unchanged and the server sends a message document indicating that the request was completed provisionally. This exception ensures that there is always at least one user (the study creator) who is authorized to reset privileges for any roleholder for the study.
For the Put Role request, the user_identifier attribute is optional; when supplied by the client, the server verifies that the user identifier in the role document matches the identifier of the roleholder to whom the role referenced in the request line belongs. If it does not match, the server responds with a 409 Conflict status code. If present, the user_name attribute is ignored. If neither the user_identifier nor the user_name attribute is included, the roleholder portion of the role document may be omitted entirely.
Similarly, the study_identifier attribute is optional; when supplied by the client, the server verifies that the study identifier in the role document matches the identifier of the study to which the role referenced in the request line adheres. If it does not match, the server responds with a 409 Conflict status code. If present, the study_name attribute is ignored. If neither the study_identifier nor the study_name attribute is included, the study portion of the role document may be omitted entirely.
Upon success, the server returns a status code of 204 No Content. Upon provisional success, the server returns a status code of 200 OK along with a message document describing the proviso.
Delete Role
In order to revoke all privileges for a user and remove the user from the roster, an authorized user makes a Delete Role request. The form of the request is:
DELETE role-location HTTP/1.1
Date: date
Host: host
{Optional headers}
Authorization: yosokumo user-identifer:request-digest
No document is sent with the DELETE request. Upon success, the server responds with a status code of 204 No Content. For the same reasons as the Put Role exception above, the role of the user who created the study cannot be deleted; an attempt to delete the study creator's role will result in the server returning a status code of 409 Conflict. A user whose role has been successfully deleted may be reauthorized in the ordinary manner by making a Post Roster request.
Before checking that a client request comes from a user that has appropriate privileges, the server must recognize the requesting user and verify that the request under consideration actually comes from that user. The server accomplishes both by examining the HTTP Authorization header sent by the client on each request.
The value of the Authorization header is composed of three main parts: the keyword "yosokumo", the requesting user's identifier, and a cryptographic message digest created using the user's private key, called the "request digest". The form of the header is:
| "Authorization:" space "yosokumo" space user-identifier ":" request-digest |
The user identifier is simply the sixteen character string assigned to the user at enrollment. This identifier is case sensitive and contains only the upper and lower case letters (a-z and A-Z) and the digits (1-9).
The request digest is created by (i) concatenating eight specific values drawn from the HTTP request line and headers, in a specific order, delimited by "+" characters, into a request string; (ii) creating a 64-byte (512-bit) SHA-512 HMAC of this request string using the secret key assigned to the requesting user at enrollment; and (iii) base64 encoding this 64-byte binary HMAC into an 88-character text string with no line breaks. The eight values that are concatenated into the request string, in order, are the:
- method from the HTTP request line
- value of the HTTP Host header
- URI from the HTTP request line
- value of the HTTP Date header
- value of the HTTP Content-Type header
- value of the HTTP Content-Length header
- value of the HTTP Content-Encoding header
- value of the HTTP Content-MD5 header
These values should be included in the request string exactly as they appear in the HTTP request, without any terminating carriage return or line feed characters. The request line and the Host and Date headers are required for an HTTP request, so the first four values are always non-empty in the request string. The final four headers need not appear in all requests; for each header that does not appear, an empty string should be concatenated onto the request string as the value for that header. The resulting string will be a single line always containing at least seven "+" characters. For example, if a client sends the following request line and headers:
GET /user.0123456789ABCDEF/catalog HTTP/1.1 User-Agent: curl/7.19.6 Host: yosokumo.ws Date: Fri, 01 Jan 2010 01:04:16 GMT Accept: */*
the request string to be digested and encoded would be:
GET+yosokumo.ws+/user.0123456789ABCDEF/catalog+Fri, 01 Jan 2010 01:04:16 GMT++++
Or a request containing headers:
POST /study.0123456789ABCDEF/table HTTP/1.1 User-Agent: curl/7.19.6 Host: yosokumo.ws:80 Date: Fri, 01 Jan 2010 01:04:16 +0000 Accept: application/yosokumo+json Content-MD5: NiBC4BRJvFTOstKYpsf/cw== Content-Length: 516 Content-Type: application/yosokumo+json
would generate the request string:
POST+yosokumo.ws:80+/study.0123456789ABCDEF/table+Fri, 01 Jan 2010 01:04:16 +0000+application/yosokumo+json+516++NiBC4BRJvFTOstKYpsf/cw==
In either case, a typical Authorization header would look like:
Authorization: yosokumo 0123456789ABCDEF:rFJPl3hrHpxOJkXkKR5T4Fa8j/Vskaf0JPp4BW7QLphx81PnXovDEs5iVKZb8oc1sjWRe9dokJ+DOYHfLQZJSg==
Note that, regardless of the order in which the HTTP headers appear in the request, the values required in the request string are always concatenated in the order listed above. Note also that the request string that is digested contains no control characters; especially, it does not include a terminating null, carriage return or line feed character.
The server authenticates the user by reconstructing the request string from the received request and recreating the message digest using the secret key known only to the server and user. In addition to verifying the correctness of the message digest, the server also checks that the timestamp contained in the Date header is within a small tolerance of the actual UTC time maintained by the server.
If the client fails to include an Authorization header, the server responds with a status code 401 Unauthorized and (as required by RFC 2616) includes an appropriate WWW-Authenticate header. If the Authorization header is not well-formed or the timestamp in the Date header is inaccurate, the server responds with a status code 400 Bad Request. If the user identified on the Authorization header is not recognized, the request digest is incorrect, or the user is recognized and authenticated but is not authorized to make the request, the server responds with 403 Forbidden.
As indicated throughout this document, the RESTful ŷosokumo protocol conforms as nearly as possible to the HTTP protocol described in RFC 2616 and its referents. The reference charts in Appendix B show the complete mapping of the core ŷosokumo protocol onto HTTP by method and resource type. The following rules summarize and expand the information in those charts.
For ŷosokumo clients:
- Requests always must include:
- a request line containing a method and resource URI
- a Host header
- a Date header with an HTTP date
- an Authorization header containing the identifier of the requesting user and an SHA-512 HMAC request digest
- When the request includes a document (such as a POST or PUT), the request:
- must include the Content-Type header indicating the DIF of the included document. The preferred forms for the value of this header for each of the supported DIFs are:
- XML: application/yosokumo+xml
- JSON: application/yosokumo+json
- Google protocol buffers: application/yosokumo+protobuf
- ASN.1: application/yosokumo+asn1
Other values are accepted by the server, provided the value can meaningfully be associated with one of the supported DIFs.
- may optionally include the Content-Encoding, Content-Length and Content-MD5 headers
- must include the Content-Type header indicating the DIF of the included document. The preferred forms for the value of this header for each of the supported DIFs are:
- Requests always may optionally include the Accept header. The DIFs listed in the header apply either to the protocol document returned or to message document that may accompany an error response. The preferred forms for the value of this header are the same as for the Content-Type header. If a request does not include the Accept header, the server sends documents in the default DIF of XML. When the request indicates that the document sent should be in the XML DIF, the request may optionally also include the x-yosokumo-namespace-prefix header; this header can be used to alter the default behavior regarding namespacing in the document (see Appendix C.2 for details).
- When the request expects a response that includes a protocol document (such as a GET request), the request may optionally include the Accept-Encoding header.
For the ŷosokumo server:
- Responses always include:
- an HTTP status code
- a Date header with an HTTP date
- When a protocol document is included in the response, the response always includes:
- a Content-Type header indicating the DIF of the included document
- a Content-MD5 header
- either a Content-Length header (if the encoding is 'identity') or a Content-Encoding header (if the encoding is not 'identity') in accordance with RFC 2616
- When the response includes a 4XX status code, and either (i) it is required by the HTTP specification; or (ii) it would be informative, secure and acceptable by the requestor, the response may include:
- a "message" document describing the reason the request was not completed
- a Content-Type header indicating the DIF of the included document
A message document takes the form:
The type attribute may contain the values 'error' or 'information'. The text attribute contains the body of the message.<message type='...'> <text>...</text> </message> - When an invalid method is requested for a resource, the response always includes:
- a 405 Method Not Allowed status code
- a Date header with an HTTP date
- an Allow header indicating the methods that are valid for the resource
- Generally, if a request includes an Accept or Accept-Encoding header that does not list a supported DIF or encoding, and the response requires a document, the server will return a status code of 406 Not Acceptable, as required by RFC 2616. However, if a POST request would have resulted in a response with a status code of 201 Created or 202 Accepted, except that the usual acknowledging document could not be sent because the request included an Accept or Accept-Encoding header that contained no supported formats, the server will nevertheless return a status code of 201 Created or 202 Accepted, respectively — rather than a status code of 406 Not Acceptable — and the document that would have been included in the response will be discarded. This allows the server to complete the request and to transmit the more important information that the request was successfully completed rather than the less important information that the acknowledging document could not be delivered.